Analysen und Wirkungsmonitoring durch exklusive wissenschaftlich validierte Methden und Modelle.
Ihre eindeutige Entscheidungsgrundlage. Ihre valide Datengrundlage. Ihre gezielte Steuerungsgrundlage.
In Zeiten zunehmender Dynamik, ist eine hohe Reaktions-, Entscheidungs- und Umsetzungsgeschwindigkeit im Dreiklang Erkenntnis/ Umsetzung/ Wirkung auf Basis hochwertiger Informationen der zentrale Erfolgsfaktor.
Wir reduzieren Komplexität und bringen alle zentralen Informationen auf den Punkt. Die Organisation als ganzheitliches System verstehen heißt, alle erfolgskritischen Ebenen zu betrachten und ihr Zusammenspiel zu kennen.
Wissen, was wirklich zählt.
Entscheidungen auf einer belastbaren und verständlichen Datengrundlage optimieren!
Genau das ist das Ziel! Einzigartig in Deutschland bringen wir in einem zehnwöchigen Kernprozess alle Themen auf den Punkt!
Treffen Sie gezielt bessere Entscheidungen auf Basis unserer Analysen. Nutzen Sie eine überzeugende Argumentationsgrundlage. Priorisieren Sie Maßnahmen strategisch. Planen und allokieren Sie Kosten zielgenau. Agieren Sie vorausschauend und präventiv!
Verstehen, wirken und Erfolge feiern!
Nutzen Sie unsere regelmäßig einsetzbare und standardisierte Diagnostik zur wissenschaftlich validierten Ableitung gezielter Maßnahmen.
Die Methoden entfalten einzeln als auch in Kombination klare Erkenntnisse, die Sie auf schnellstem Weg in Umsetzung und Wirkung bringen.

Komplementär und kombinierbar
Alle Instrumente sind aufeinander abgestimmt. Sie ermöglichen einen kombinierten Einsatz und unterschiedliche Analysetiefen.
Exklusiv und High End!
Unsere Tools wurden und werden vom ehemaligen Präsidenten der Deutschen Gesellschaft für Psychologie und unserem Wissenschaftsteam exklusiv für unsere Kunden entwickelt.
Schnell, hocheffizient, maximale Erklärungskraft!
Unsere Lösungen wie bspw. in den Themen Gefährdungsbeurteilung psychischer Belastung oder Digitale Transformation setzen den effizientesten Standard im deutschsprachigen Raum. Sie bieten ein deutlich höheres Vorhersagepotenzial als andere Skalen trotz deutlich weniger Items. Betriebliche Abläufe werden nur minimal beansprucht.
Klarheit und Konsistenz
Wir schaffen Wissen und Transparenz sowie Verständnis, Sprech- und Handlungsfähigkeit. Jedes Projekt basiert auf einer klaren Kommunikation, die Ängste ab- und Bereitschaft sowie Unterstützung aufbaut und alle wichtigen Akteure einbezieht.
Hochflexibel die freie Wahl!
Egal ob Online-Offline-Befragung, Feinanalysen in Fokusgruppen, Workshop-Formaten oder Beobachtungsinterview – entscheiden Sie selbst. Alle Lösungen sind selbsterklärend, intuitiv nutzbar und einfach zu bedienen.
Voll digital und klassisch!
Alle Tools sind digital und webbasiert und laufen auf Smartphone, Tablet oder PC. Natürlich sind alle Analysen auch klassisch im Paper-Pencil-Format einsetzbar und frei mit allen Online-Lösungen kombinierbar.
Auf den Punkt!
Aussagekräftig aufbereitet bieten die Auswertungen einen prägnanten Gesamtüberblick und einen kompletten Einblick, sprich eine detaillierte punktgenaue Betrachtung.
Pulsmesser und Frühwarnsystem!
Ein zusätzliches Monitoring durch unser Frühwarnsystem youCcom company index ermöglicht schnelles Reagieren auf kritische Veränderungen durch Evaluations- und Performance-Maße, die unseren exklusiven Methoden zugrunde liegen.
Gezielte Auswahl, effiziente Kombination, kontextbezogene Entwicklung, nachhaltige Bindung und überlegte Wiedergewinnung!
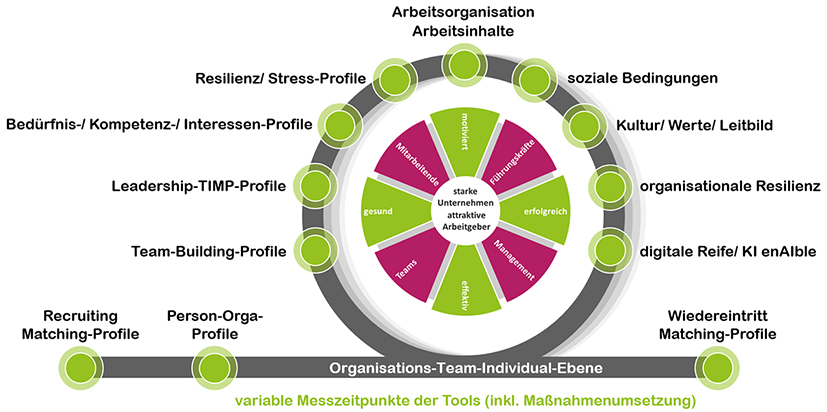
Unsere Tools erfassen den kompletten Lebenszyklus Ihrer Mitarbeitenden, in den jeweiligen Rollen und den Arbeitsbedingungen innerhalb der Organisation.
Anhand komplementärer Bausteine machen wir jede Station im Organisations-Mitarbeitenden-Lebenszyklus mess- und interpretierbar.
Wir zeichnen ein konsistentes Bild auf Organisations-, Team- und Individualebene.
Organisationsentwicklung auf Basis aussagekräftiger Analysen und einem kurzzyklischen Wirkungsmonitoring
Wir bilden Arbeitsbedingungen anhand von Arbeitsorganisation, -inhalten, sozialen Bedingungen und Umgebungsbedingungen ab und erfassen Anforderungsprofile aller Arbeitsplätze.
Team
Auf Team- und Projekt-Team-Ebene messen wir, was Teams effizient macht. Team-Rollen sowie Team-Profilanalysen ermöglichen die optimale Grundlage für den Aufbau von Teams, gezielte Teambesetzung, sowie Teamveränderungsprozessgestaltung, um die Grundlage für gute Zusammenarbeit in jeglicher Konstellation zu schaffen.
Individuum
Auf Mitarbeitenden- Führungskraft-Ebene messen wir, was den Menschen stärkt, um ihn gezielt zu unterstützen.
Mitarbeiter-Ebene
Führungskraft-Ebene